서버는 aws ec2, 데이터베이스는 aws rds를 사용했다. 둘 다 프리티어로 사용했다.
사용자가 입력한 질문과 데이터베이스에 있는 질문들의 유사도를 측정한 뒤, 사용자의 질문과 비슷한 질문들을 출력해주는 기능을 만들고 싶었다. 추천 시스템과 비슷하게 모든 문서의 tf-idf를 구한 후 코사인 유사도 검사를 하면 될 것 같아서 그대로 진행했다.
우선 비교 데이터로 사용하기 위해 OKKY라는 사이트의 Q&A게시판을 크롤링했다. 10000개 게시글의 질문과 내용을 크롤링해서 csv파일로 만든 후 데이터베이스에 넣어두었다. 테이블의 칼럼은 bid, title, content 로 만들었다.
그 다음 데이터베이스에 있는 데이터들을 사용하기 위해서 지난 번에 만들어둔 tf-idf-test 모듈을 최적화한 후에 사용했다.
2022.06.26 - [JavaScript/자연어 처리] - [node.js] JavaScript TF-IDF, 코사인 유사도 검사
tf-idf-test 모듈은 문서가 어떤 과정을 통해 벡터로 변환되는지, 변환된 벡터로 어떻게 코사인 유사도 검사가 실행되는지 알아보기 위해 만들었기 때문에 시간복잡도와 공간복잡도에 대한 고려없이 구현했었다. 실제로 test 모듈로 10000개의 질문과 임의의 질문 하나를 비교하려고 하면 메모리 초과가 발생해서 실행자체를 못했다. 프리티어 ec2에서 사용가능한 램이 500MB가 채 되지 않았기 때문에 서버에서 사용할 최적화된 모듈이 따로 필요했다.
시간복잡도와 공간복잡도를 줄이기 위해 사용한 방법은 아래와 같다.
1. 비교데이터의 tf-idf를 미리 계산해둔 파일을 저장함
2. tf 벡터를 만들 때 csr 행렬을 사용함
3. 코사인 유사도 검사할 때 투포인터 알고리즘을 사용함
1. 비교데이터의 tf-idf를 미리 계산해둔 파일을 저장함
1번부터 설명해보자면 우선 두 단계로 나눠서 진행했다. 첫 번째 단계는 비교데이터를 토큰화한 파일을 저장하는 것이고 두 번째 단계는 토큰화한 파일을 불러와서 tf-idf를 계산한 뒤 파일로 저장하는 것이다.

위의 사진과 같이 형태소 분석기 mecab이 한 문서를 토큰화하는데 걸리는 시간이 4~5ms 였다. 따라서 만개를 토큰화한다면 40~50초, 백만개를 토큰화한다면 4000~5000초가 걸리는 것이다. 토큰화할 때 고정적으로 소요되는 시간이 너무 컸기에, 제일 먼저 토큰화한 파일을 저장해야 겠다고 생각했다. 토큰화한 파일을 불러와서 tf-idf를 계산하는 것은 성공적이었다.
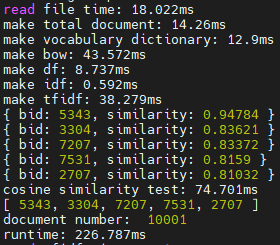
토큰화할 때 필요한 40~50초의 시간을 절약했다.
그 다음은 tf-idf를 계산하는 시간이었다. 위의 사진에서 보면 tf-idf를 만들기위해 걸리는 시간은 대략 실행시간의 절반이다. 그래서 비교데이터를 토큰화한 데이터 뿐만 아니라 tf-idf까지 계산한 데이터를 파일로 저장하고 사용하면 더 빠를 것 같다고 생각했다. 또한 tf-idf파일을 불러오는 시간을 절약하기 위해서 서버를 킬 때 tf-idf파일을 메모리에 올려둔 다음 사용했다.
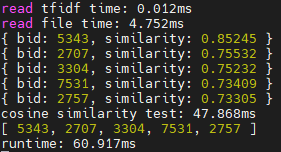
시간이 많이 줄었지만 유사한 문서의 목록이 조금 바뀐 것을 확인할 수 있다. 사실 비교데이터의 tf-idf를 미리 계산하는 것은 공식상 완벽한 구현은 아니다. 왜냐하면 임의의 질문과 비교데이터를 합친 다음 tf-idf를 계산해야 온전한 단어사전, idf 값이 나오기 때문이다. tf-idf를 미리 계산하게 되면 단어사전에 임의의 질문안에 있는 단어들이 빠지게 되고 결국 tf-idf 값이 변하게 된다. 그래서 직접 해당 id의 질문을 찾아봤는데 기존 방식으로 찾은 질문들과 크게 다르지 않아서 그대로 사용했다.
2. tf 벡터를 만들 때 csr 행렬을 사용함
2번은 공간복잡도를 줄이기 위해 사용한 방법이다. 한 문서의 tf 벡터의 칼럼 수는 단어사전에 있는 단어의 수와 같다. 단어사전에 1000개의 단어가 있다면 tf 벡터의 칼럼이 1000개인 것이다. 그래서 아래 사진과 같이 tf 벡터가 0으로 가득한 것을 확인할 수 있다.

문서마다 다르겠지만 내가 사용할 문장 단위의 경우 0이 아닌 데이터가 많아봐야 10개인 아주 희소한 벡터이다. 따라서 이 벡터들을 합쳐서 희소행렬을 만든 후 csr 행렬을 사용해야 겠다고 생각했다. csr 행렬은 Compressed Sparse Row 행렬의 줄임말인데 희소행렬을 압축하는 방법 중 하나이다. 아래의 블로그 설명이 가장 도움이 됐다.
https://gaussian37.github.io/math-la-sparse_matrix/
각 문서의 tf 벡터가 행이 되고, 단어사전의 index가 열이 되는 행렬을 생각한 후, 이 행렬을 csr 행렬로 만들었다. 그 결과 만개 비교데이터의 tf-idf 파일의 크기는 866KB가 됐다. 희소벡터를 그대로 사용했을 때는 500MB 램이 부족했었지만 행렬을 압축하니 데이터 크기가 매우 작아졌다.
3. 코사인 유사도 검사할 때 투포인터 알고리즘을 사용함
3번은 시간복잡도를 줄이기 위해 사용한 방법이다. 위의 방법들을 적용한 뒤 만개 데이터를 복사해서 100만개의 데이터로 테스트를 해봤다. 임의의 질문과 100만개의 질문을 비교했을 때 걸린 평균 시간은 약 2초였다.

서버 메모리에 올려놓은 tf-idf 데이터를 사용하기 때문에 소요 시간은
1. 임의의 질문의 tf-idf를 구하는 시간
2. 구한 tf-idf와 서버의 tf-idf 데이터를 합치는 시간
3. 코사인 유사도 검사하는 시간
4. 유사도를 내림차순으로 정렬하는 시간
으로 나뉜다.
여기서 1번과 2번은 고정시간이고 1ms가 채 안걸린다.
3번이 1~2초, 4번이 0.5~0.6초 정도 걸렸다.
3번 코사인 유사도 검사하는 시간부터 줄였다.
코사인 유사도 검사에서 가장 오래걸리는 부분은 스칼라 곱을 구해야 하는지 체크하는 부분이다. A문서의 토큰과 B문서의 토큰을 비교해서 서로 공통된 토큰이 있을 때 스칼라 곱을 구하게 된다. 공통분모를 찾을 때 A문서의 토큰 개수를 N개, B문서의 토큰 개수를 M개라고 가정하고 2중 for문을 사용하면 시간복잡도는 O(N*M) 가 된다. 그래서 이 부분에 투포인터를 사용하면 시간을 줄일 수 있을거라고 생각했다.
기존 코드는 아래와 같다.
// 스칼라곱 구하기
for(let j in last_data){// 마지막 문서의 tfidf 개수만큼
for(let k in comp_data){// i번 문서의 tfidf 개수만큼
// 마지막 문서의 tfidf벡터와 i번 문서의 tfidf벡터의 스칼라곱
if(last_col[j] === comp_col[k]){
scalar_product += last_data[j] * comp_data[k];
break;
}
}
}
위의 부분을 투포인터를 사용해서 시간복잡도를 O(N+M) 로 줄였다. 투포인터를 사용하기 위해 csr 행렬을 만들 때 각 row의 column을 오름차순으로 정렬시켰다.
// 스칼라곱 구하기 투포인터
let last_pointer = 0;
let comp_pointer = 0;
let last_end = last_data.length - 1;
let comp_end = comp_data.length - 1;
while(1){
if(last_pointer>last_end || comp_pointer>comp_end){
break;
}
if(last_col[last_pointer] === comp_col[comp_pointer]){
scalar_product += last_data[last_pointer] * comp_data[comp_pointer];
last_pointer++;
comp_pointer++;
}
else if(last_col[last_pointer] < comp_col[comp_pointer]){
last_pointer++;
}
else if(comp_col[comp_pointer] < last_col[last_pointer]){
comp_pointer++;
}
}
4번 유사도를 내림차순으로 정렬하는 시간도 줄였다.
이 부분은 단순하게 유사도가 0.1 이하이면 정렬하는 배열에 넣지 않는 방식으로 해결했다.
| 1번 문장 | 파이썬 | 크롤링 | 방법 | 질문 |
| 2번 문장 | 자바 | 패키지 | 사용 | 질문 |
위와 같이 토큰화된 문장이 있었는데, 두 문장에서 공통적으로 등장한 단어는 '질문'이었다. '질문'은 10000개의 질문글 중에 3000개 이상의 질문글에 등장한 단어였다. 따라서 tf-idf 가중치가 낮을 것으로 예상했고 실제로 두 문장의 유사도는 0.17이었다. 이 사례를 보고 문장 단위의 유사도 검사에서 0.1 이하의 데이터는 의미가 없다고 생각해서 정렬 시간을 줄이기 위해 0.1 이하 데이터는 배열에 넣지 않았다.
코드를 수정한 후 다시 테스트한 결과는 아래와 같다.

100만개 질문글을 비교하는 시간이 기존의 2.26초에서 0.56초로 줄었다. 약 75%정도가 감소했다.
평소에 코딩하면서 생각하기 힘든 시간복잡도와 공간복잡도를 이번에 서버에서 사용할 기능을 구현하면서 많이 고민해본 것 같다. 형태소는 명사만 사용했었는데, 모든 형태소를 추출하고 불용어를 처리하는 방식으로 바꿔볼 예정이다.
아래는 test 모듈을 변형한 simple-tf-idf-db.js의 코드다.
function tokenizer(document){
let mecab = require('mecab-ya');
let tokenized_document = [];
for(let i in document){
tokenized_document.push(mecab.nounsSync(document[i]));
}
return tokenized_document;
}
function build_bag_of_words(bid, tokenized_document){
let word_to_index = new Map();
let total_document = [];
let bow = {};
let row = [];
let col = [];
let data = [];
let N = tokenized_document.length;
// 하나의 문서로 통합
for(let index in tokenized_document){
for(let j in tokenized_document[index]){
total_document.push(tokenized_document[index][j]);
}
}
//console.log('total document : ', total_document);
// 단어에 index 맵핑
for(let word in total_document){
if(word_to_index.get(total_document[word]) == null){
// 처음 등장하는 단어 처리
word_to_index.set(total_document[word], word_to_index.size);
}
}
// csr형식으로 bow 만들기
row.push(0);
for(let index in tokenized_document){
col_temp = [];
data_temp = [];
let bow_temp = [];
let bow_obj = {};
for(let word in tokenized_document[index]){
let i = word_to_index.get(tokenized_document[index][word]);
if(bow_temp.length === 0){
// 오름차순을 위한 객체
bow_obj = {
'col':i,
'data':1,
}
bow_temp.push(bow_obj);
}
else{
let flag = 0;
for(let k in bow_temp){
if(bow_temp[k].col === i){
bow_temp[k].data++;
flag = 1;
break;
}
}
if(flag === 0){
bow_obj = {
'col':i,
'data':1,
}
bow_temp.push(bow_obj);
}
}
}
row.push(bow_temp.length + row[index]);
bow_temp.sort(function(a, b) {
return a.col - b.col;
});
for(let i in bow_temp){
col.push(bow_temp[i].col);
data.push(bow_temp[i].data);
}
}
bow = {
'numberOfDocuments':N,
'row':row,
'col':col,
'data':data,
'bid':bid,
}
//console.log('vocabulary : ', word_to_index);
//console.log('bag of words vectors(term frequency) : ', bow);
return [word_to_index, bow];
}
function get_idf(bow, vocab){
let df = [];
df.length = vocab.size;
df.fill(0);
// df 구하기
for(let i in bow.col){// 등장하는 column과 동일한 index의 값을 1씩 증가시킴
df[bow.col[i]]++;
}
//console.log('document frequency : ', df);
let idf = [];
let N = bow['numberOfDocuments']; // 전체 문서의 수
idf.length = vocab.size;
idf.fill(0);
// idf 구하기
for(let i in idf){
idf[i] = 1 + Math.log((1 + N) / (1 + df[i])); // 자연로그
}
//console.log('inverse document frequency : ',idf);
return idf;
}
function get_tfidf(bow, idf){
// tfidf 구하기
let tfidf = {};
let data_temp = [];
for(let i in bow.data){// data 개수만큼
data_temp.push(bow.data[i] * idf[bow.col[i]]);
}
tfidf = {
'numberOfDocuments':bow.numberOfDocuments,
'row':bow.row,
'col':bow.col,
'data':data_temp,
'bid':bow.bid,
}
//console.log('TF-IDF : ', tfidf);
return tfidf;
}
function cosine_similarity(tfidf){
//0번 문서와 다른 모든 문서를 비교해서 코사인 유사도를 구함
let cos_sim = [];
let zero_row = tfidf.row[1] - tfidf.row[0];
let zero_col = [];
let zero_data = [];
for(let i=0;i<zero_row;i++){// 0번 문서의 colmun과 data를 추출
zero_col.push(tfidf.col[i]);
zero_data.push(tfidf.data[i]);
}
let normalized_zero = normalize(zero_data);
console.time('cal');
for(let i=0;i<tfidf.numberOfDocuments;i++){// 전체 문서에 대해
let scalar_product = 0;
let comp_row = tfidf.row[i+1];
let comp_col = [];
let comp_data = [];
for(let j=tfidf.row[i];j<comp_row;j++){// i번 문서의 colmun과 data를 추출
comp_col.push(tfidf.col[j]);
comp_data.push(tfidf.data[j]);
}
// 스칼라곱 구하기
for(let j in zero_data){// 0번 문서의 tfidf 개수만큼
for(let k in comp_data){// i번 문서의 tfidf 개수만큼
// 0번 문서의 tfidf벡터와 i번 문서의 tfidf벡터의 스칼라곱
if(zero_col[j] === comp_col[k]){
scalar_product += zero_data[j] * comp_data[k];
break;
}
}
}
let cos_sim_temp = 0;
if(scalar_product === 0){
// 스칼라곱이 0이면 코사인 유사도는 0
cos_sim_temp = 0;
}
else{
// 스칼라곱이 0이 아니면 코사인 유사도 공식 사용
cos_sim_temp = scalar_product / (normalized_zero * normalize(comp_data));
cos_sim_temp = Number(cos_sim_temp.toFixed(4));
}
let cos_sim_obj = {
'id':i,
'similarity':cos_sim_temp,
}
cos_sim.push(cos_sim_obj);
}
console.timeEnd('cal');
// 유사도 내림차순 정렬
console.time('sort');
cos_sim.sort(function(a, b) {
return b.similarity - a.similarity;
});
console.timeEnd('sort');
// 상위 5개의 bid만 추출
let top5_cos_sim_id = [];
for(let i=1; i<6; i++){
console.log(cos_sim[i]);
top5_cos_sim_id.push(cos_sim[i].id);
}
return top5_cos_sim_id;
}
function cosine_similarity_lastnum(tfidf){
// 마지막 문서와 다른 모든 문서를 비교해서 코사인 유사도를 구함
let cos_sim = [];
let N = tfidf.numberOfDocuments;
let last_row = tfidf.row[N] - tfidf.row[N-1];
let last_col = [];
let last_data = [];
let last_col_start_index = tfidf.col.length - last_row;
for(let i=last_col_start_index;i<tfidf.col.length;i++){// 마지막 문서의 colmun과 data를 추출
last_col.push(tfidf.col[i]);
last_data.push(tfidf.data[i]);
}
//console.log(last_col);
//console.log(last_data);
//console.log(tfidf);
let normalized_last = normalize(last_data);
console.time('cal');
for(let i=0;i<tfidf.numberOfDocuments;i++){// 전체 문서에 대해
let scalar_product = 0;
let comp_row = tfidf.row[i+1];
let comp_col = [];
let comp_data = [];
for(let j=tfidf.row[i];j<comp_row;j++){// i번 문서의 colmun과 data를 추출
comp_col.push(tfidf.col[j]);
comp_data.push(tfidf.data[j]);
}
// 스칼라곱 구하기 투포인터
let last_pointer = 0;
let comp_pointer = 0;
let last_end = last_data.length - 1;
let comp_end = comp_data.length - 1;
while(1){
if(last_pointer>last_end || comp_pointer>comp_end){
break;
}
if(last_col[last_pointer] === comp_col[comp_pointer]){
scalar_product += last_data[last_pointer] * comp_data[comp_pointer];
last_pointer++;
comp_pointer++;
}
else if(last_col[last_pointer] < comp_col[comp_pointer]){
last_pointer++;
}
else if(comp_col[comp_pointer] < last_col[last_pointer]){
comp_pointer++;
}
}
let cos_sim_temp = 0;
if(scalar_product === 0){
// 스칼라곱이 0이면 코사인 유사도는 0
continue;
//cos_sim_temp = 0;
}
else{
// 스칼라곱이 0이 아니면 코사인 유사도 공식 사용
cos_sim_temp = scalar_product / (normalized_last * normalize(comp_data));
cos_sim_temp = Number(cos_sim_temp.toFixed(4));
}
if(cos_sim_temp > 0.1){ // 유사도가 0.1이하면 넘어감
let cos_sim_obj = {
'id':i,
'similarity':cos_sim_temp,
}
cos_sim.push(cos_sim_obj);
}
}
// 유사한 문서가 없을 경우
if(cos_sim.length === 0){
console.log('no similar post');
return;
}
console.timeEnd('cal');
// 유사도 내림차순 정렬
console.time('sort');
cos_sim.sort(function(a, b) {
return b.similarity - a.similarity;
});
console.timeEnd('sort');
//console.log(cos_sim);
// 상위 5개의 bid만 추출
let top5_cos_sim_id = [];
for(let i=1; i<6; i++){
console.log(cos_sim[i]);
top5_cos_sim_id.push(cos_sim[i].id);
}
return top5_cos_sim_id;
}
function similarity_test(document){
console.time('time');
// 문서 토큰화
let tokenized_document = tokenizer(document);
//console.log('tokenized_document : ', tokenized_document);
// 모든 단어에 index 맵핑
let result = build_bag_of_words(tokenized_document);
let vocab = result[0];
let bow = result[1];
// 모든 단어의 idf 구하기
let idf = get_idf(bow, vocab);
// 모든 문서의 tfidf 구하기
let tfidf = get_tfidf(bow, idf);
// 0번 문서와 나머지 문서의 유사도 검사
let cos_sim = cosine_similarity(tfidf);
// 유사한 5개 문서 출력
for(let i in cos_sim){
console.log('id : ', cos_sim[i], ', ', document[cos_sim[i]]);
}
console.timeEnd('time');
}
function similarity_test_token(tokenized_document){
console.time('time');
// 모든 단어에 index 맵핑
let result = build_bag_of_words(tokenized_document);
let vocab = result[0];
let bow = result[1];
// 모든 단어의 idf 구하기
let idf = get_idf(bow, vocab);
// 모든 문서의 tfidf 구하기
let tfidf = get_tfidf(bow, idf);
// 0번 문서와 나머지 문서의 유사도 검사
let cos_sim = cosine_similarity(tfidf);
console.timeEnd('time');
}
function normalize(vector){
// 벡터 정규화 공식
let sum_square = 0;
for(let i in vector){
sum_square += vector[i] * vector[i];
}
return Math.sqrt(sum_square);
}
function save_document_file(path, document){
const fs = require('fs');
fs.writeFile(path, JSON.stringify(document), err => {
if(err){
console.error(err);
return;
}
else{
console.log('document saved in : ', path);
}
});
}
function load_document_file(path){
const fs = require('fs');
let readData = fs.readFileSync(path);
return JSON.parse(readData.toString());
}
function tokenize_DBdata(path){
let DBdata = load_document_file(path);
let bid = [];
let title = [];
for(let i in DBdata){
bid.push(DBdata[i].bid);
title.push(DBdata[i].title);
}
let tokenized_title = tokenizer(title);
return [bid, tokenized_title];
}
module.exports = {
tokenizer,
build_bag_of_words,
get_idf,
get_tfidf,
cosine_similarity,
cosine_similarity_lastnum,
similarity_test,
similarity_test_token,
save_document_file,
load_document_file,
tokenize_DBdata,
};
아래는 토큰화한 파일 저장, tf-idf 계산한 파일 저장, 토큰화된 파일과 임의의 질문 비교, tf-idf파일과 임의의 질문 비교하는 js 모듈이다.
const simpleTfidfDB = require('./simple-tf-idf-db');
console.log('HI');
let data_num = '1m';
let server_tfidf = simpleTfidfDB.load_document_file('./data/' + data_num +'_tfidf_DBdata');
console.log('load ' + data_num +'_tfidf_DBdata file to memory');
function save_token_DBdata(){
console.log('data_num : ', data_num);
console.time('runtime');
let path = './data/' + data_num +'_DBdata';
let result = simpleTfidfDB.tokenize_DBdata(path);
let bid = result[0];
let title = result[1];
path = './data/' + data_num +'_token_DBdata';
simpleTfidfDB.save_document_file(path, result);
console.timeEnd('runtime');
}
function make_big_DBdata(){
let path = './data/10k_token_DBdata';
let result = simpleTfidfDB.load_document_file(path);
for(let i=0;i<99;i++){
for(let j=0;j<10000;j++){
result[0].push(result[0][j]);
result[1].push(result[1][j]);
}
}
path = './data/1m_token_DBdata';
simpleTfidfDB.save_document_file(path, result);
}
function save_tfidf_DBdata(){
console.time('runtime');
let document = [];
// 미리 토큰화된 DBdata 가져오기
let path = './data/' + data_num +'_token_DBdata';
let token_DBdata = simpleTfidfDB.load_document_file(path);
let bid = token_DBdata[0];
let token_title = token_DBdata[1];
// 모든 단어에 index 매핑
let bow_result = simpleTfidfDB.build_bag_of_words(bid, token_title);
let vocab = bow_result[0];
let bow = bow_result[1];
let vocab_obj = [];
for(const [key, value] of vocab){
let temp_obj ={
key: key,
value: value
};
vocab_obj.push(temp_obj);
}
path = './data/' + data_num +'_vocab_DBdata';
simpleTfidfDB.save_document_file(path, vocab_obj);
// 모든 단어의 idf 구하기
let idf = simpleTfidfDB.get_idf(bow, vocab);
path = './data/' + data_num +'_idf_DBdata';
simpleTfidfDB.save_document_file(path, idf);
// 모든 문서의 tfidf 구하기
let tfidf = simpleTfidfDB.get_tfidf(bow, idf);
path = './data/' + data_num +'_tfidf_DBdata';
simpleTfidfDB.save_document_file(path, tfidf);
console.timeEnd('runtime');
}
function NLP_token_file(){
// 미리 토큰화된 파일과 사용자의 질문 비교
console.time('runtime');
let document = [];
// 미리 토큰화된 DBdata 가져오기
let path = './data/' + data_num +'_token_DBdata';
let token_DBdata = simpleTfidfDB.load_document_file(path);
let bid = token_DBdata[0];
let token_title = token_DBdata[1];
let UserQ = {
bid: 0,
title: '파이썬으로 크롤링하는 방법 질문이요',
};
let temp = [];
temp.push(UserQ.title);
// 유저의 질문과 토큰화된 문서 합치기
let tokenized_UserQ = simpleTfidfDB.tokenizer(temp);
bid.unshift(UserQ.bid);
token_title.unshift(tokenized_UserQ[0]);
// 모든 단어에 index 매핑
let result = simpleTfidfDB.build_bag_of_words(bid, token_title);
let vocab = result[0];
let bow = result[1];
// 모든 단어의 idf 구하기
let idf = simpleTfidfDB.get_idf(bow, vocab);
// 모든 문서의 tfidf 구하기
let tfidf = simpleTfidfDB.get_tfidf(bow, idf);
// 0번 문서와 나머지 문서의 유사도 검사
let cos_sim = simpleTfidfDB.cosine_similarity(tfidf);
let top5bid = [];
for(let i=0;i<5;i++){
top5bid.push(bid[cos_sim[i]]);
}
console.log(cos_sim);
console.log(top5bid);
console.timeEnd('runtime');
}
function NLP_tfidf_file(){
// 미리 계산된 tfidf 파일과 사용자의 질문 비교
console.time('runtime');
let document = [];
let UserQ = {
bid: 0,
title: '파이썬으로 크롤링하는 방법 질문이요',
};
let temp = [];
temp.push(UserQ.title);
// 유저 질문 토큰화
let tokenized_UserQ = simpleTfidfDB.tokenizer(temp);
tokenized_UserQ = tokenized_UserQ[0];
console.log(tokenized_UserQ);
console.time('read file time');
// 미리 저장된 단어 사전 불러오기
let path = './data/' + data_num +'_vocab_DBdata';
let vocab_file = simpleTfidfDB.load_document_file(path);
let vocab = new Map();
for(let i in vocab_file){
vocab.set(vocab_file[i].key, vocab_file[i].value);
}
//console.log(vocab);
// 미리 저장된 idf 불러오기
path = './data/' + data_num +'_idf_DBdata';
let idf = simpleTfidfDB.load_document_file(path);
//console.log(idf);
// 미리 저장된 tfidf 불러오기
console.time('read tfidf time');
path = './data/' + data_num +'_tfidf_DBdata';
//let tfidf = simpleTfidfDB.load_document_file(path);
let tfidf = server_tfidf;
//console.log(tfidf);
console.timeEnd('read tfidf time');
console.timeEnd('read file time');
// 유저 질문 tf 구하기
row_temp = 0;
col_temp = [];
data_temp = [];
let bow_temp = [];
let bow_obj = {};
for(let word in tokenized_UserQ){
let i = vocab.get(tokenized_UserQ[word]);
//console.log(tokenized_UserQ[word],' : ',i);
if(i == null){
continue;
}
if(col_temp.length === 0){
bow_obj = {
'col':i,
'data':1,
}
bow_temp.push(bow_obj);
}
else{
let flag = 0;
for(let k in bow_temp){
if(bow_temp[k].col === i){
bow_temp[k].data++;
flag = 1;
break;
}
}
if(flag === 0){
bow_obj = {
'col':i,
'data':1,
}
bow_temp.push(bow_obj);
}
}
}
// 유저 질문과 유사한 문서가 없을 경우(단어사전에 유저의 질문 토큰이 없는 경우)
if(bow_temp.length === 0){
console.log('no similar post');
return;
}
bow_temp.sort(function(a, b) {
return a.col - b.col;
});
for(let i in bow_temp){
col_temp.push(bow_temp[i].col);
data_temp.push(bow_temp[i].data);
}
row_temp = col_temp.length;
// 유저 질문 tfidf 구하기
for(let i in col_temp){
data_temp[i] = data_temp[i] * idf[col_temp[i]];
}
//console.log(row_temp);
//console.log(col_temp);
//console.log(data_temp);
//console.log(tfidf);
// 유저 질문 tfidf를 미리 저장된 tfidf와 합침
console.time('assemble');
/*// 유저 질문tfidf를 0번에 넣어서 합침
for(let i in tfidf.row){
tfidf.row[i] +=row_temp;
}
tfidf.row.unshift(0);
tfidf.bid.unshift(0);
for(let i in col_temp){
tfidf.col.unshift(col_temp[col_temp.length - 1 - i]);
tfidf.data.unshift(data_temp[col_temp.length - 1 - i]);
}
*/
// 유저 질문 tfidf를 마지막 번호에 넣어서 합침
let N = tfidf.numberOfDocuments;
tfidf.numberOfDocuments++;
tfidf.row.push(tfidf.row[N] + row_temp);
tfidf.bid.push(0);
for(let i in col_temp){
tfidf.col.push(col_temp[i]);
tfidf.data.push(data_temp[i]);
}
//console.log(row_temp);
//console.log(col_temp);
//console.log(data_temp);
//console.log(tfidf);
console.timeEnd('assemble');
// 유저 질문 tfidf와 미리 저장된 tfidf값을 코사인 유사도 검사함
console.time('user cos_sim time');
let cos_sim = simpleTfidfDB.cosine_similarity_lastnum(tfidf);
let top5bid = [];
for(let i=0;i<5;i++){
top5bid.push(tfidf.bid[cos_sim[i]]);
}
console.log(cos_sim);
console.log(top5bid);
console.timeEnd('user cos_sim time');
// tfidf에서 마지막 문서를 제거
tfidf.numberOfDocuments--;
tfidf.row.pop();
tfidf.bid.pop();
for(let i in col_temp){
tfidf.col.pop();
tfidf.data.pop();
}
console.timeEnd('runtime');
}
module.exports = {
save_token_DBdata,
make_big_DBdata,
save_tfidf_DBdata,
NLP_token_file,
NLP_tfidf_file,
};
아래는 크롤링한 데이터를 토큰화, tf-idf를 계산한 파일이다. 위의 모듈을 사용해서 확인할 수 있다.
참고한 사이트
4) TF-IDF(Term Frequency-Inverse Document Frequency)
이번에는 DTM 내에 있는 각 단어에 대한 중요도를 계산할 수 있는 TF-IDF 가중치에 대해서 알아보겠습니다. TF-IDF를 사용하면, 기존의 DTM을 사용하는 것보다 보 ...
wikidocs.net
https://gaussian37.github.io/math-la-sparse_matrix/
sparse matrix (희소 행렬)와 CSR(Compressed Sparse Row)
gaussian37's blog
gaussian37.github.io
[알고리즘] 투 포인터 (Two pointers) 알고리즘
투 포인터란? 이번 글에서는 Two pointers technique (algorithm)을 설명해보도록 하겠습니다. 일단 이름 그대로 두 가지 포인터를 사용하여 문자열이나 배열(또는 리스트)에서 원하는 값을 찾거나 반복문
benn.tistory.com
기록용입니다.
'JavaScript > 자연어 처리' 카테고리의 다른 글
| [node.js] JavaScript TF-IDF, 코사인 유사도 검사 (0) | 2022.06.26 |
|---|---|
| [node.js] 형태소 분석기 mecab 사용하기 (1) | 2022.06.25 |